MoSCoW Achievement Table
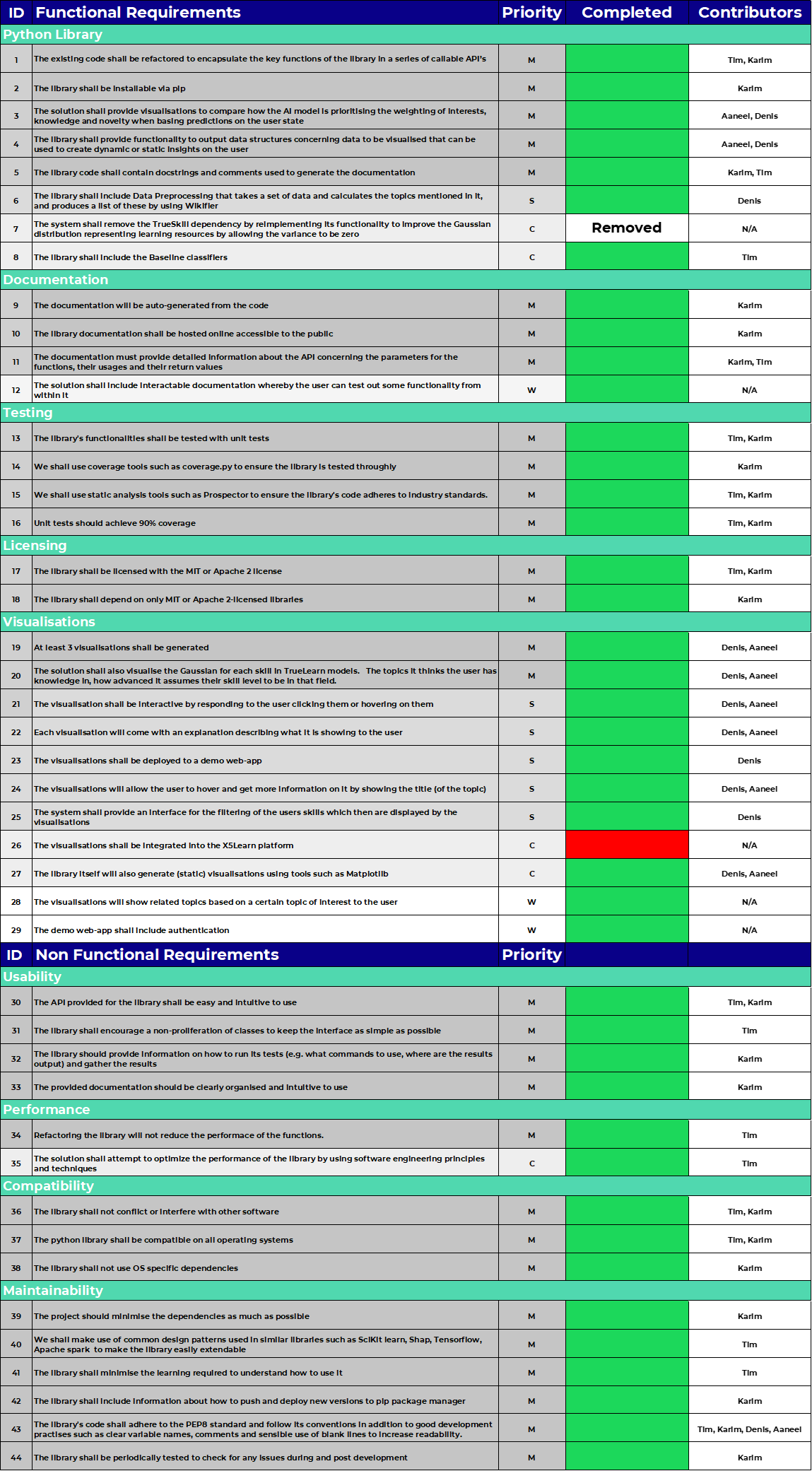
Key Functionalities (Must Haves and Should Haves): 100% (39/39)
Optional Functionalities (Could Haves): 80% (4/5)
Total: 98% (43/44)
List of Known Bugs
None.
Individual Contribution Distribution Table

Critical Evaluation of the Project
User Experience
During the development of this project, we based our decision-making upon what users of our library are looking for.
On the learner side, we focus on producing interpretable and insightful visualizations to track and guide their learning journey.
- We studied research papers (“What Learning Visualisations to Offer Students” by Susan Bull and “Individual and Peer Comparison Open Learner Model Visualisations to Identify What to Work On Next” by Susan Bull) on effective visualisations that students find the most helpful and understandable and finalised on nine different types of visualisations: Bar Charts, Line Charts, Dot Plots, Pie Charts, Rose Charts, Bubble Charts, Tree Maps, Radar Charts and Word Clouds. These visualisations inform users on their skill level across different subjects, the level of certainty of our prediction as well as how this has developed over time.
- We used a universal colour-scale “Greens” (which is a shade rather than several different colours) due to feedback from our client that this is this is an easily understandable way, to depict the skill level of users and its certainty level.
On the developer side, we focused on adhering to design principles mentioned in our literature review, such as "Consistency", “Inspections” and “Sensible Defaults.”
- Consistency: All the classifiers in truelearn library has the same and consistent
interface. For training, all the classifiers have
fitmethod, and for prediction, all the classifiers havepredictandpredict_probafunction. - Inspection: All the classes in
truelearn.modelsandtruelearn.learningare inspectable, which means developers can inspect the internal states of these classes via either getter/setter or exposed@property. - Sensible Defaults: Parameters are key parts of all the classifiers. To reduce the time cost of researching on different parameters for users, we provide an appropriate default value to each parameter. The default value is not necessarily the best in a custom use case but provides sensible results in general. Based on our evaluation of the default values chosen in our tests, it is reasonable to say that our classifier has sensible default values.
Overall, we would say we did Very Good in this aspect.
Functionality
We have always focused on the key design target, which is about modelling learners' knowledge, predicting their engagement with educational resources and providing insightful visualisations to help learners reflect on their study. We delivered 100% (36 out of 36) of the key functionalities we intended to deliver and 50% (3 out of 6) of the optional functionalities on our MoSCoW list. Without diving too deep, these include but not limited to:
- Build a model of a learner's knowledge from their learning history
- Predict learners' engagement based on their past learning events
- Create various kinds of visualizations that highlight changes in users' knowledge over time and users' understanding of different knowledge
Overall, we would say we did Very Good in this aspect.
Stability
Throughout the development process, we followed an intensive testing procedure. We achieved 100% on code coverage of core functionalities of truelearn library (models, learning, datasets, preprocessing, utils.metrics). We also deploy a list of linters that statically analyse our codebase based on different perspectives (code quality, code style, documentation style, security, type checking). All of these are checked on every commit by using CI/CD.
Overall, we would say we did Good in this aspect.
Efficiency
Throughout our development process, we continuously looked for ways to do optimizations and
do timing profiling by using hyperfine to study how our refactoring affects the
wall clock
running time of our application. As stated in the “Testing/Performance Testing” section, we
improved the running time of the NoveltyClassifier by about 20%, significantly
reduced the
number of memory allocations (by more 50%) and slightly decreased the overall memory
consumption.
Overall, we would say we did Very Good in this aspect.
Compatibility
Building on top of Python, our library is naturally compatible with different operating systems (OSX, Linux, Windows). In terms of Python version support, we choose to support any Python version between 3.7 (the earliest version that has not ended its lifecycle yet) and 3.11(the latest release). To ensure that these compatibility guarantees were not broken, we deploy ci checks on these 3 operating systems and these 5 Python versions, which is 3*5=15 checks in total.
For dependencies, we choose them carefully by considering their API stability, minimal Python version support (which must be Python 3.7+), and license (which must be a permissive license). This allows us to balance functionality support with our compatibility guarantees and licensing option (MIT license).
Overall, we would say we did Very Good in this aspect.
Maintainability
Another key aspect we prioritised was maintainability.
We made sure that any future development would be seamless process by including comprehensive type annotations, explanations and examples for every method and class in our documentation. We also provide contributors with detailed guidelines on how to set up a Truelearn development environment, design new components, create new tests and submit PRs.
In terms of codebase, we utilised multiple design patterns to make sure our code is easily extensible and loosely coupled. Each public method and class are tested thoroughly by using doc tests and unit tests. At the same time, we established a consistent code style in the codebase based on PEP8, Google Python Style Guide, and Black Code Style, and implemented strict ci checks (prospector-pydocstyle, typos, black), which further reduced maintenance costs.
Overall, we would say we did Very Good in this aspect.
Project management
The team worked well together. Throughout the 15 weeks, we made sure to produce a to-do list on a weekly basis. Each task was assigned to team members alongside a deadline. We stuck to our deadlines well. We organised weekly meetings with our clients and ourselves outside of labs. Some meetings were cancelled due to train strikes or if it were not needed. Every member played their part to ensure the success of the project.
Overall, we would say we did Very Good in this aspect.
Future Work
- Explore real-world application: we intend to bring the exciting functionalities and visualisations of truelearn library to x5Learn, an open-education platform. In terms of data, x5learn has divided all videos into 5-minute segments, extracted the Wikipedia topics within each segment and was able to record user engagement through their algorithm. Thus, to integrate TrueLearn into their platform, we only need to study how to integrate our model into their backend API and database and embed visualisations into their React-based WebApp.
- Extend Classifiers: currently, the developers can only run a simple version of TrueLearn experiments by using our library. To allow them to easily replicate the entire TrueLearn experiment, we can add supports for classifiers that are based on knowledge tracing and methods that can perform hyperparameter training.
- Improve Documentation: we can improve the user experience of our documentation by introducing interactive code snippets that allow users to execute examples in our documentation in their browsers. To achieve this, we need to research on WASM, which allows us to run Python in browser.
- Explore Semantic Information: currently, classifiers in truelearn library does not utilize any information between different knowledge components. For example, machine learning and linear regression are treated as different unrelated topics (but there are connections between them). In theory, the relationships between different topics give us more information about the learner and can therefore, boost the performance (accuracy, precision, recall, and f1) of the truelearn classifiers. These semantic relationships also allow us to design new visualisations. For example, we can group related topics into categories and create category-based visualisations. To achieve this, we need to integrate semantic TrueLearn https://discovery.ucl.ac.uk/id/eprint/10141501/ into our library, which entails extending the current model sub-package (storing Semantic Relatedness (SR) annotations) and implementing the semantics algorithm logic in the learning sub-package.