Models
Models of the learner and learning events are essential parts of the TrueLearn library as they form the basis of the classification and prediction algorithms. These representations are found in truelearn.models .
Representing Knowledge
The Knowledge Component (KC) is the atomic unit of knowledge used in the TrueLearn library. It represents a Wikipedia topic with an associated mean and variance. The mean represents the estimated skill associated with that KC. The variance represents the confidence of the estimation.
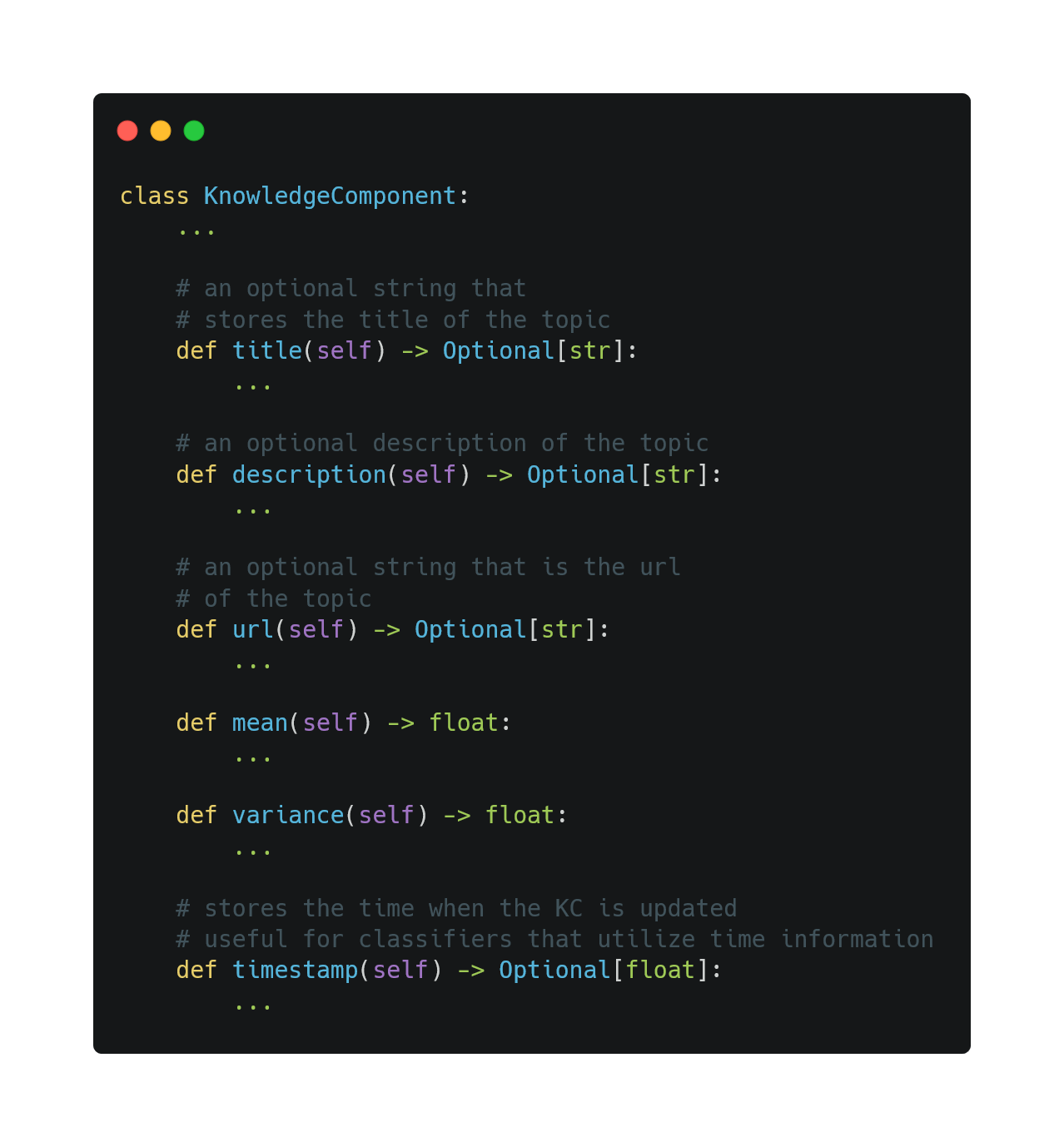
As KC is the atomic unit of knowledge, we design a class Knowledge to group and store KCs by their id.
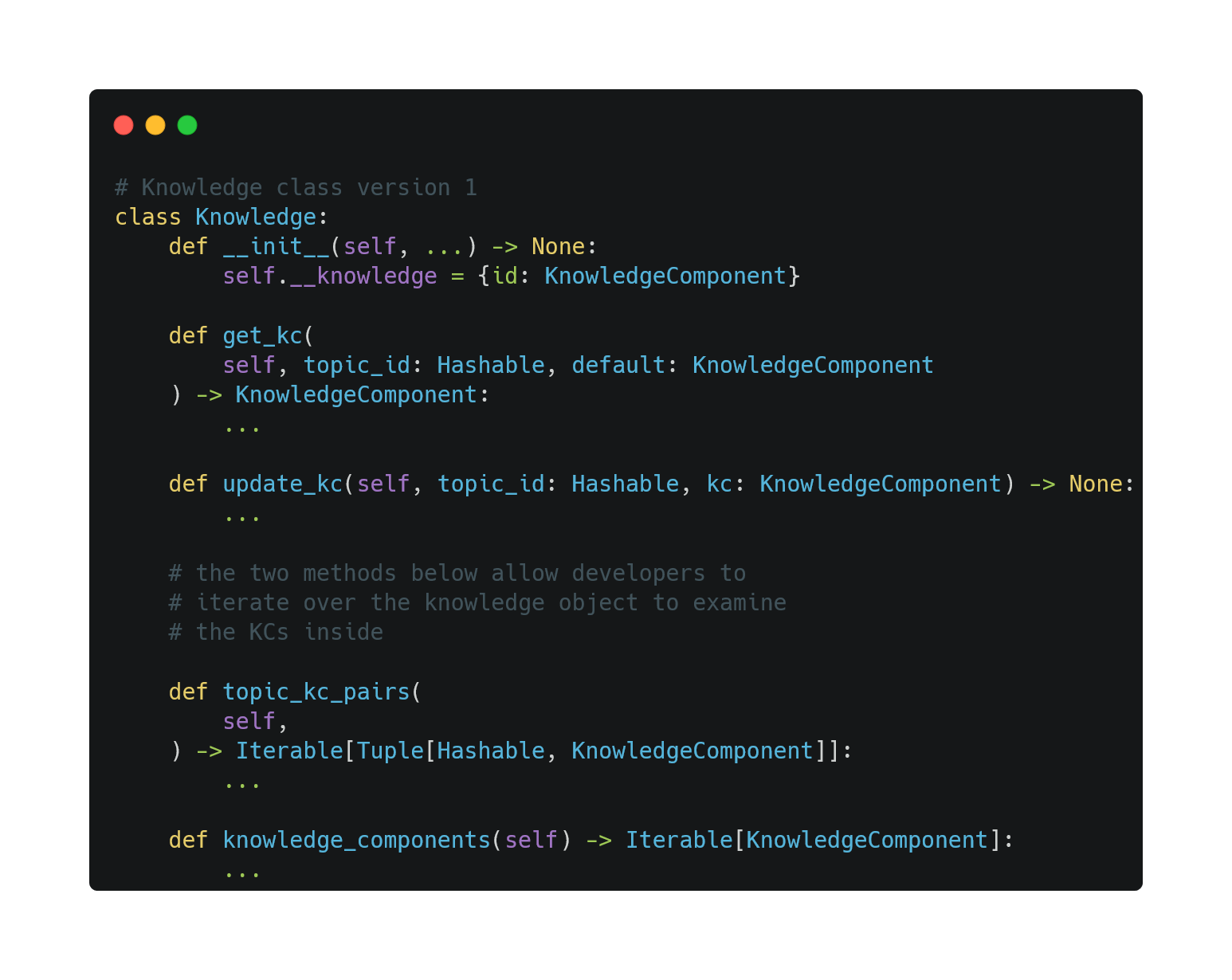
The Knowledge class is used to model the learner and event.
For the learner, the KC in Knowledge estimates how well the learner knows about this topic. For the event, the KC in knowledge estimates how well the learning event covers the topic.
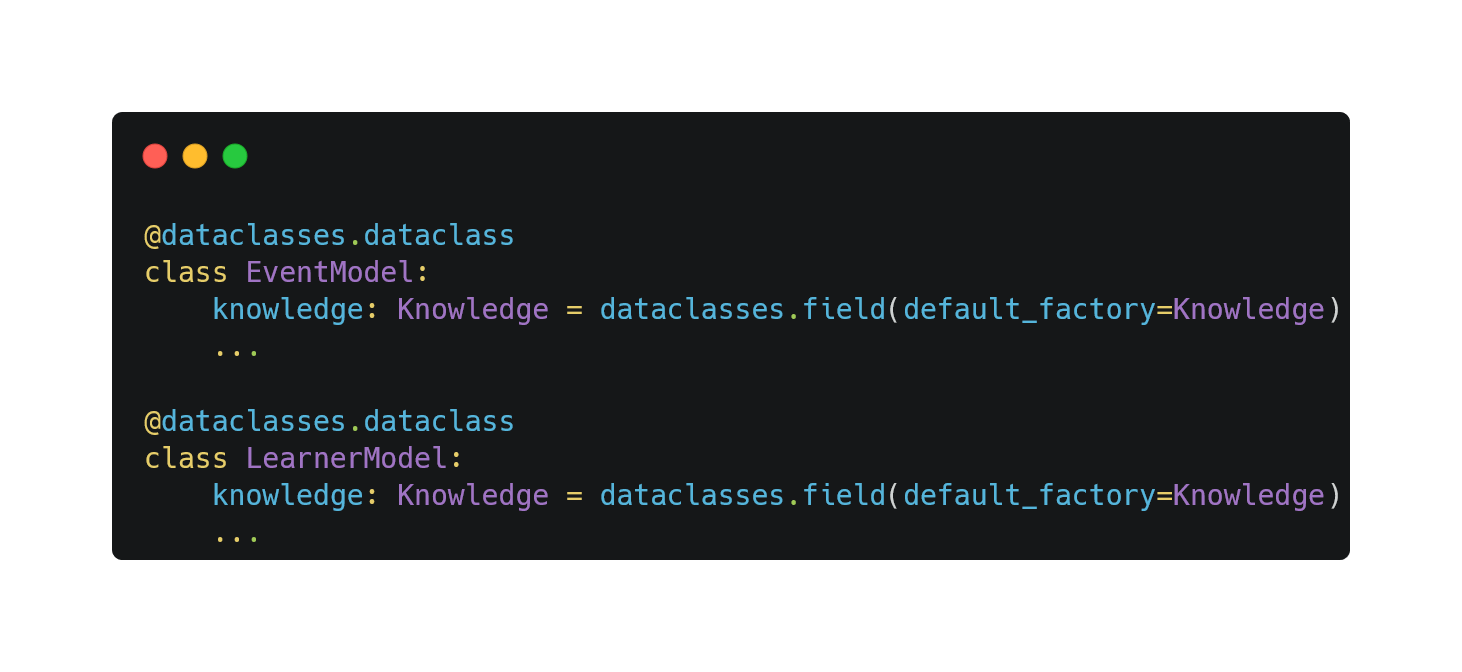
Extendable Knowledge Components
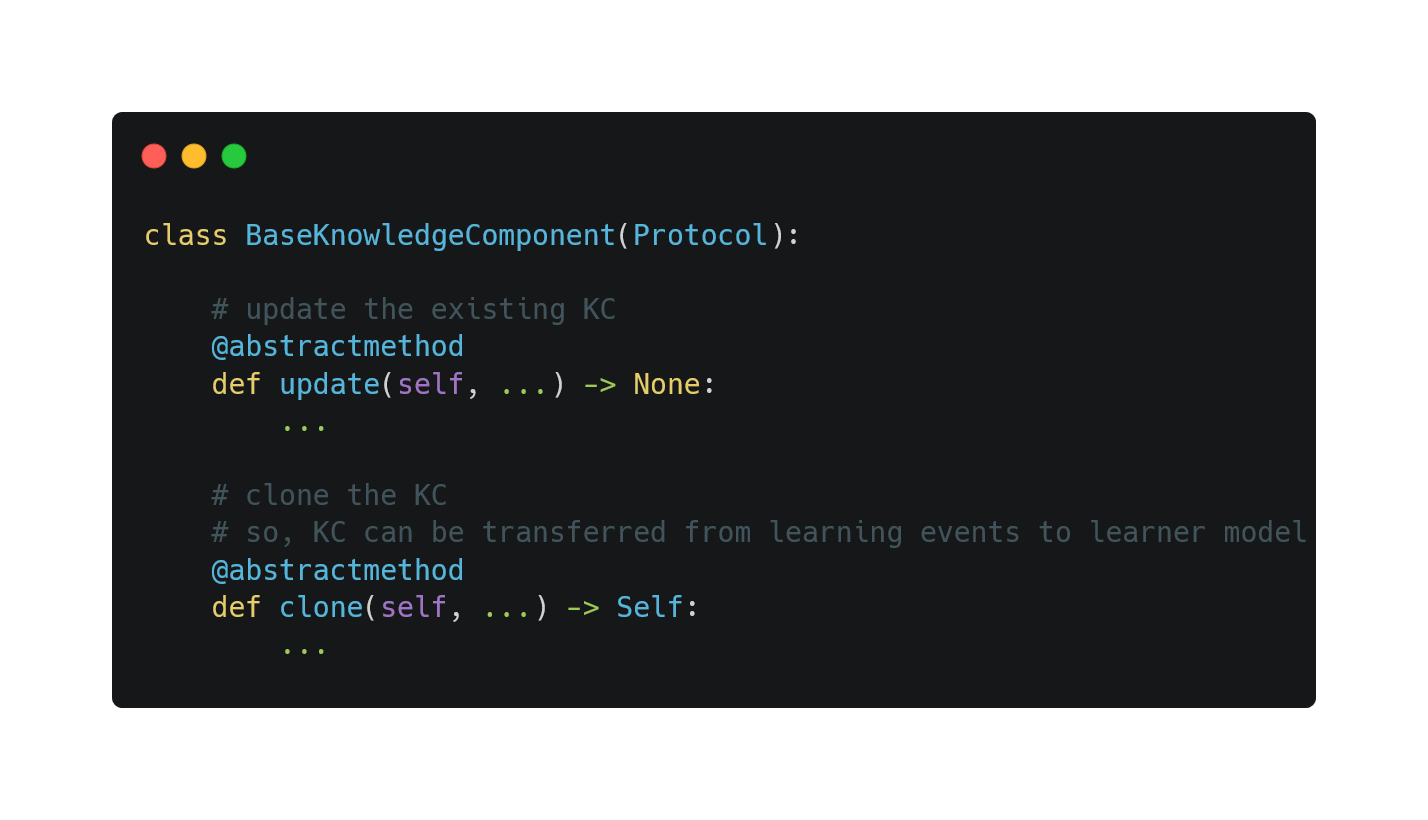
To ensure developers can freely extend the KC class based on their application, we avoid referring to KnowledgeComponent directly in Knowledge. Instead, we define an interface BaseKnowledgeComponent that specifies the public APIs for all KCs.

With the interface above, the implementation of Knowledge does not need to refer to any concrete implementation.
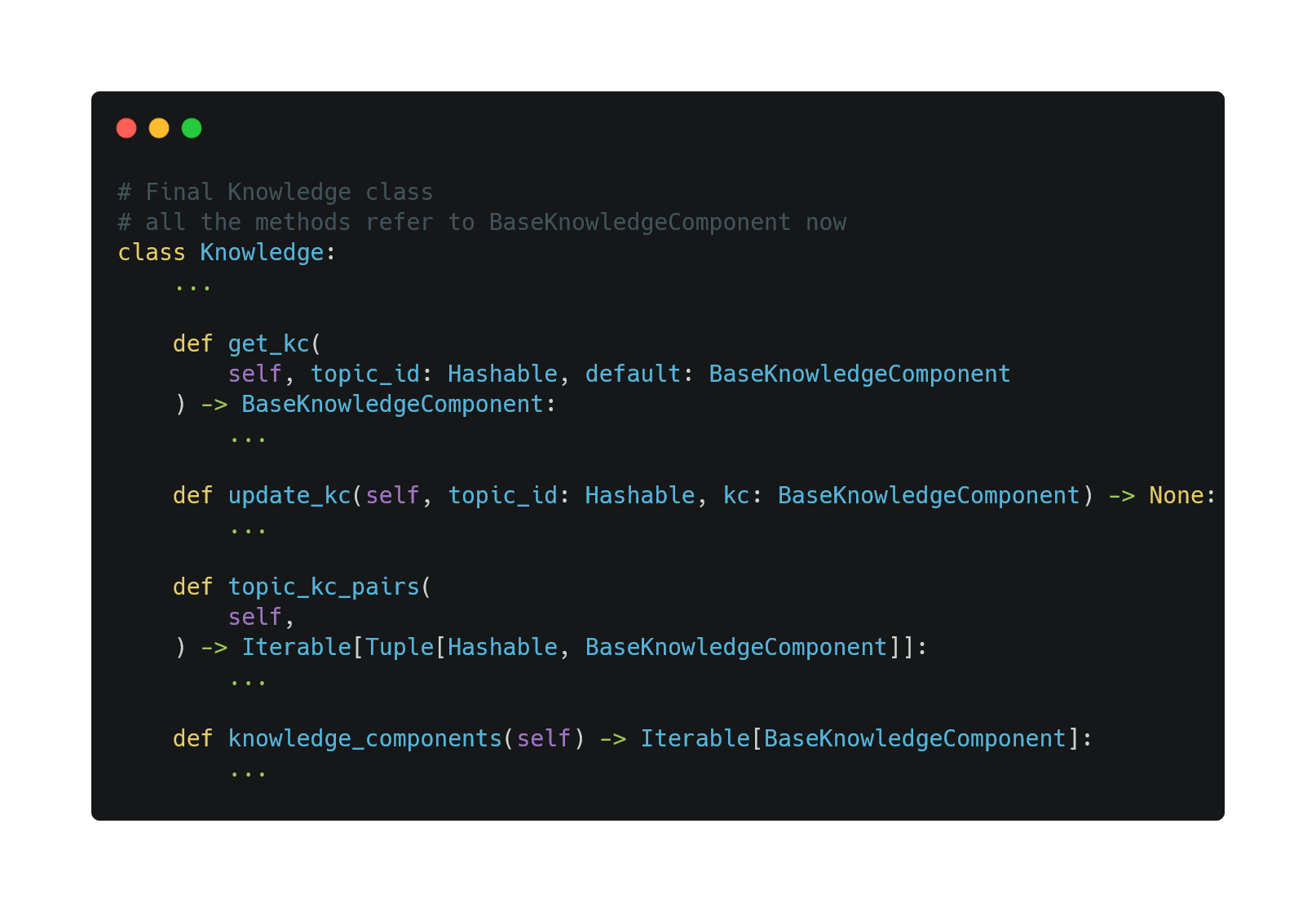
Updating and Transferring Knowledge
As a family of Bayesian algorithms, Truelearn classifiers, which utilise the truelearn.models, need to update the prior estimation of the existing KCs and create new KCs in the learner model based on the given learning event.
Thus, we specify two additional APIs in BaseKnowledgeComponent that all KCs need to implement.
Classifiers
The truelearn.learning sub-package implements all the classifiers in the truelearn library.
Dependencies
-
trueskill: a rating system among game players. It was developed by Microsoft Research and has been used on Xbox LIVE for ranking and matchmaking services. This system quantifies players’ TRUE skill points by the Bayesian inference algorithm.
-
mpmath: a free (BSD licensed) Python library for real and complex floating-point arithmetic with arbitrary precision.
Public Interface Walkthrough
Based on what we outlined in our study, we designed a BaseClassifier class to ensure a consistent interface across all our classifiers.
The class BaseClassifier follows the naming convention of the scikit-learn library:
- The
fitmethod is used to train the classifier - The
predictandpredict_probamethods use the classifier to make predictions. - The
get_paramsandset_paramsmethods are used to get or set the parameters of the classifier.

Defining Parameter Constraints
When the developer initializes the classifier, they need to pass in the parameters for the classifier. Then, the classifier implementer usually needs to implement checks inside classifiers to verify that the given parameters have the correct type and value. To simplify this process and provide a simple yet powerful way to validate parameters, we used parameter constraints.
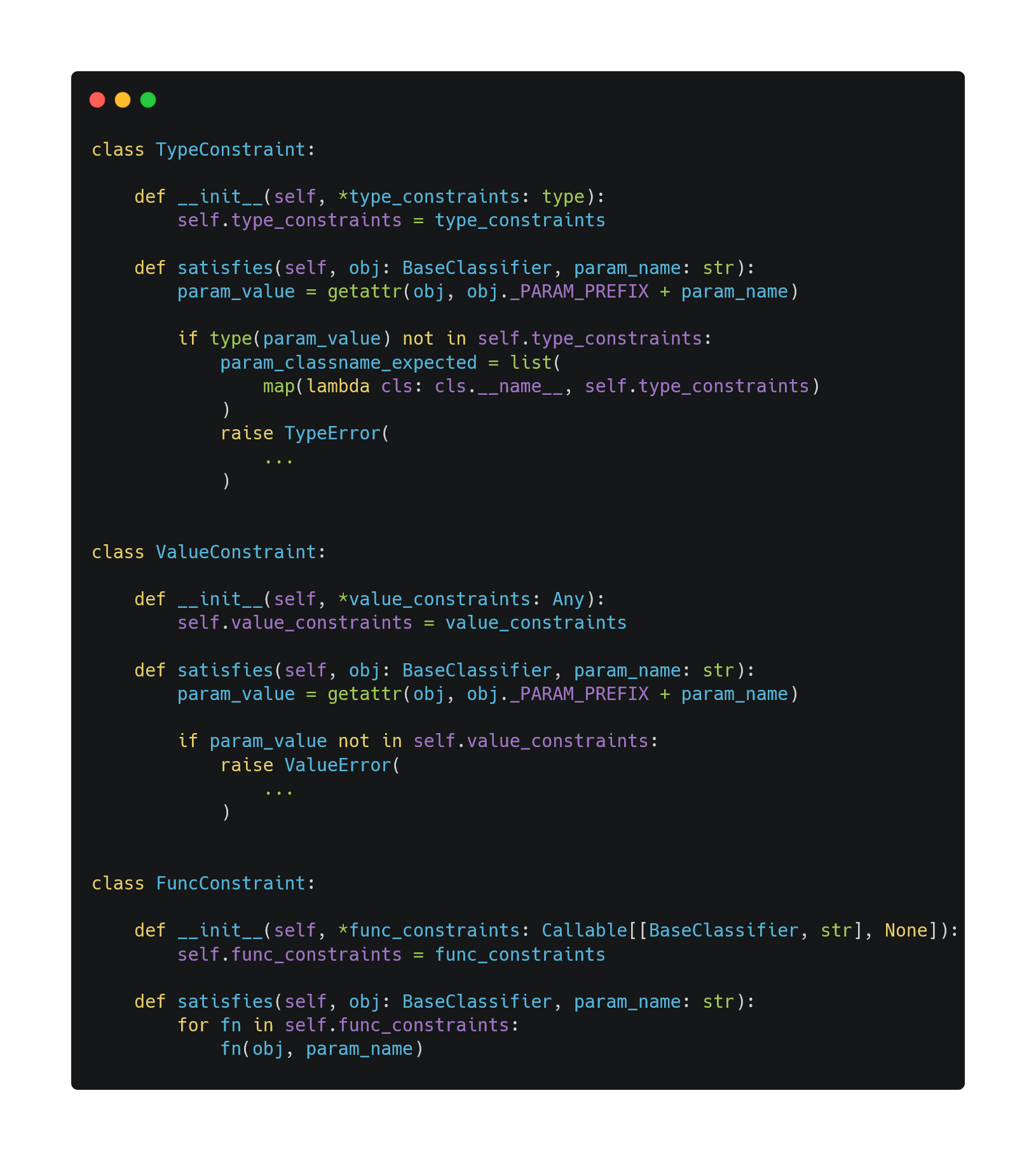
There are three kinds of ways to express different constraints on parameters. TypeConstraint ensures the type of the parameters must match one of the types in the TypeConstraint class. ValueConstraint checks if the value of the parameters matches one of the values in the ValueConstraint class. FuncConstraint ensures that the parameters satisfy some user-defined functions.
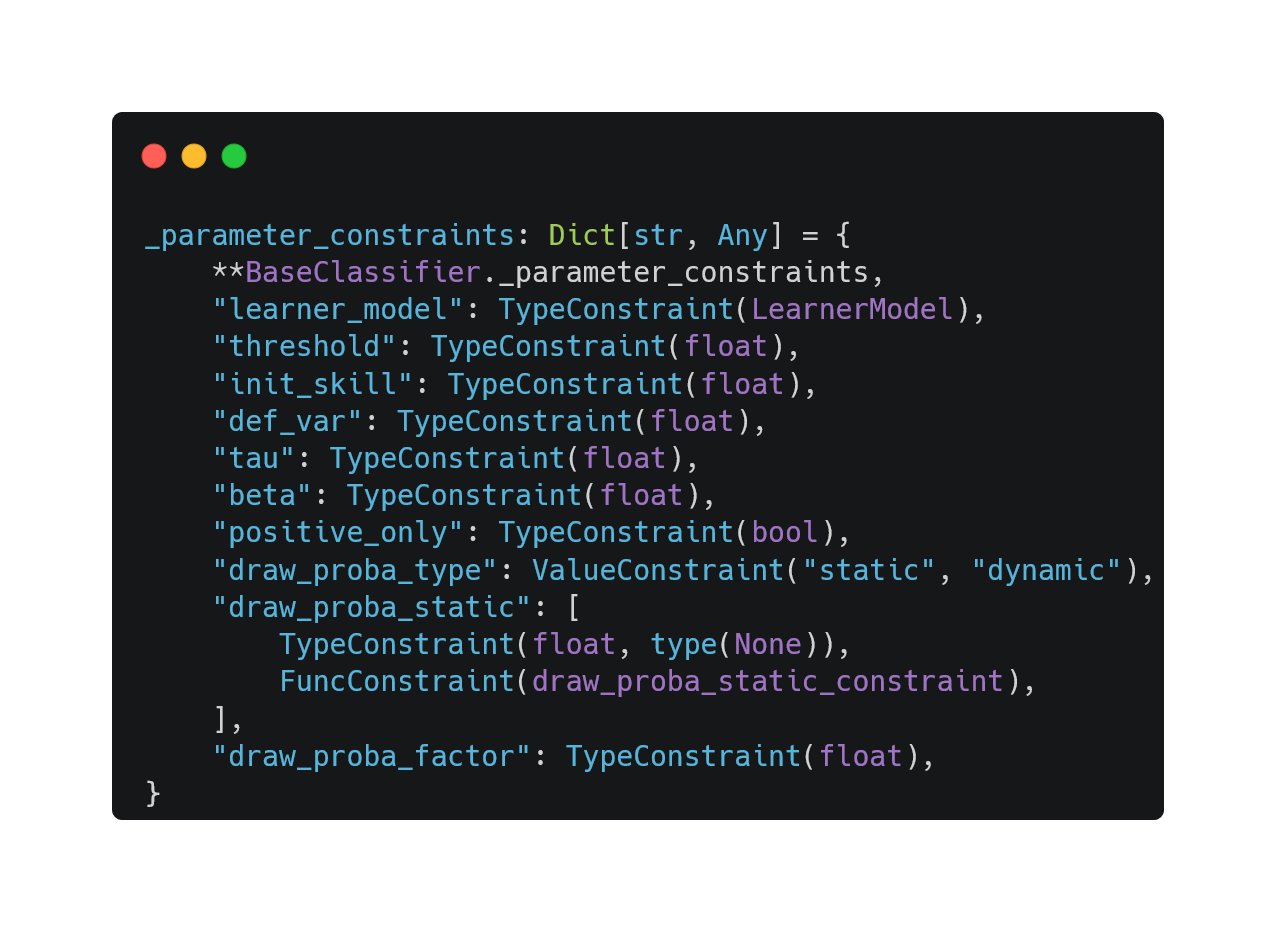
Then, in all classifiers, we define a class attribute _parameter_constraints, which maps parameter names to a constraint or a list of constraints.
When the classifier object is initialized, or its parameters are changed via set_params, the classifier runs a check to verify that all parameters satisfy the constraints.

Getting and Setting Parameters
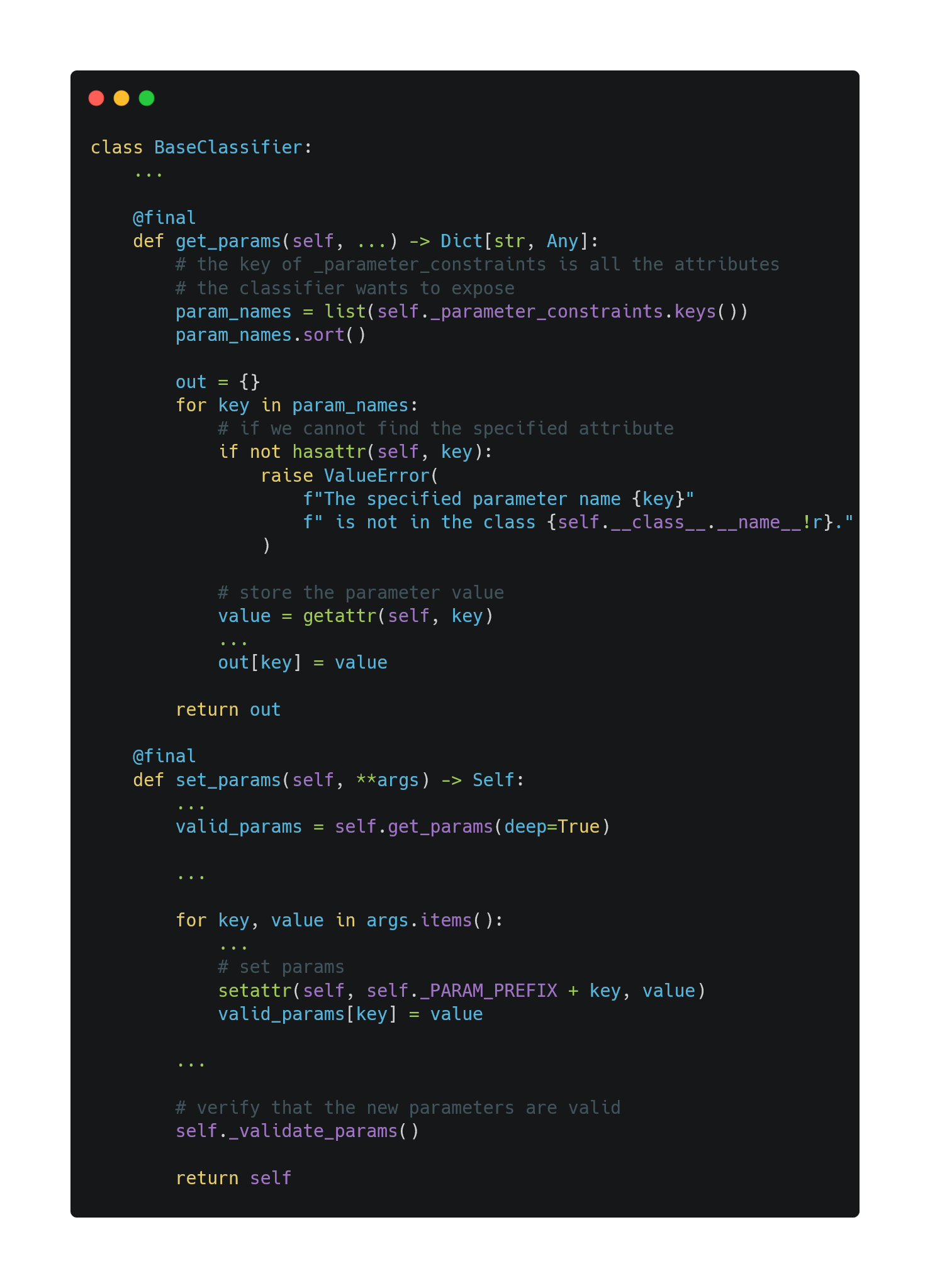
To reduce code redundancy, we implement get_params and set_params in BaseClassifier. We use the Python reflection mechanism via hasattr, getattr and setattr to do this, as we need to support the inspection and modification of any classifier object at runtime.
Training the Classifier
The core part of truelearn.learning is three classifiers (KnowledgeClassifier, NoveltyClassifier and InterestClassifier).
The methods used to train them are not identical but follow a similar pattern. Thus, we apply the template pattern when implementing fit. First, these three classifiers have a positive_only mode, during which the classifiers update the learner model iff the learner engages in the given event x. Second, besides the learner model, the classifiers also update some statistics related to the model via self.__update_engagement_stats, which is always invoked regardless of the positive_only mode.
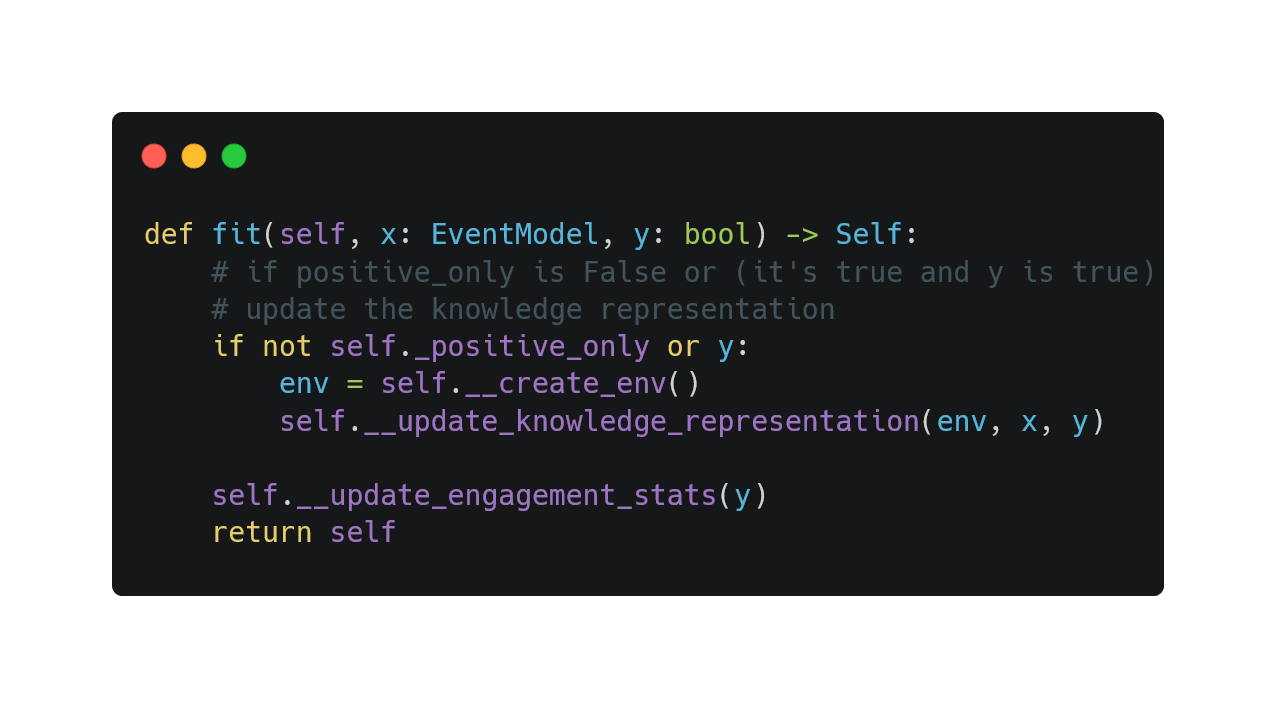
In __update_knowledge_representation, we also apply the strategy pattern as this process can be divided into three parts:
- based on the given KCs in the event model, create (in case the corresponding KCs are not in the learner model) or select KCs from the learner model
- update the selected KCs
- commit the changes to the learner model
It turns out that part 1 and part 3 are the same across these 3 classifiers. They only differ in how they update the selected KCs (the self._generate_ratings method). Thus, we define the following template for __update_knowledge_representation.
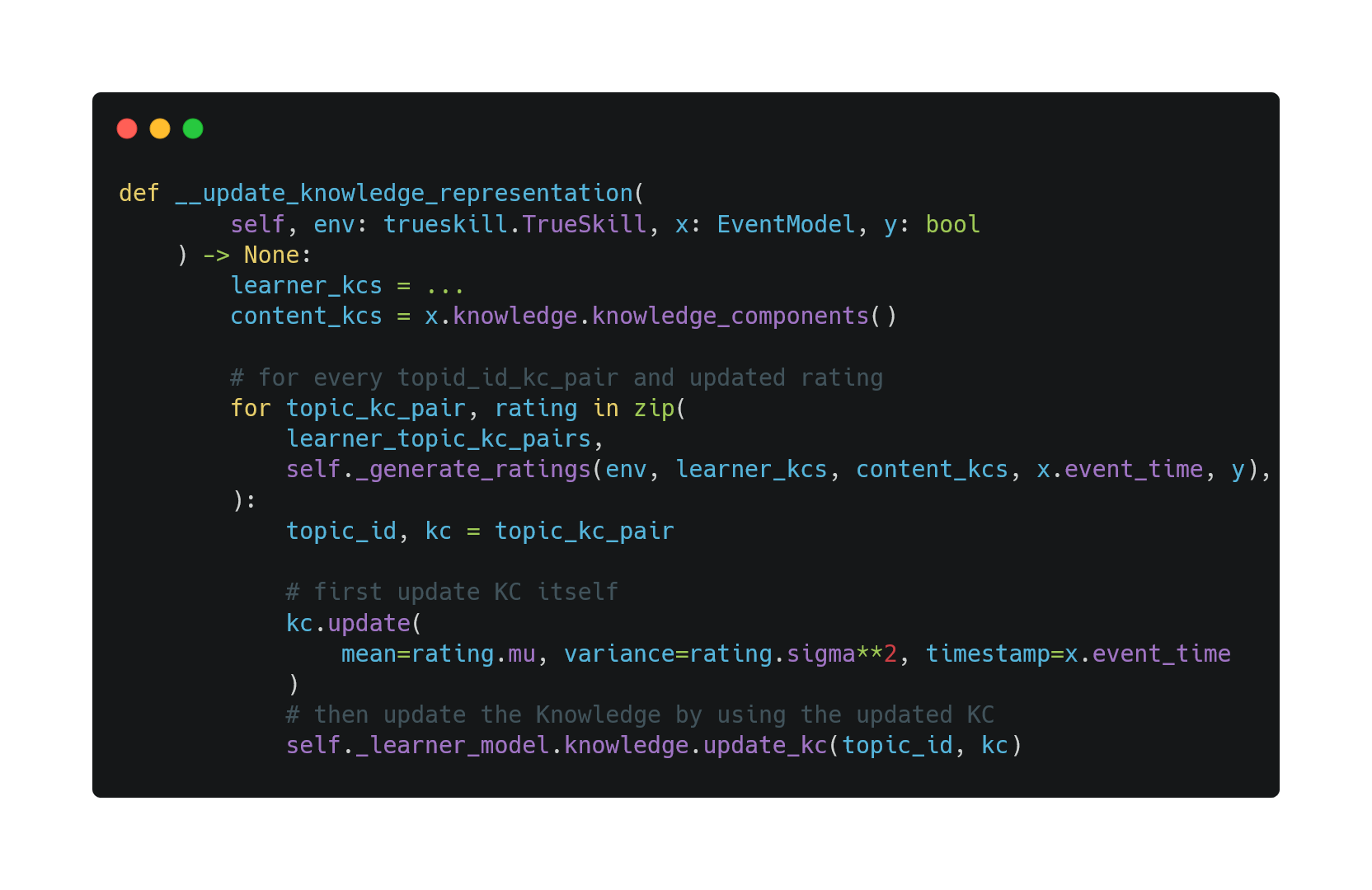
The method left to each classifier is self._generate_ratings since each classifier relies on different hypotheses presented in the TrueLearn paper and updates the selected KCs differently.
Predicting Learner Engagement
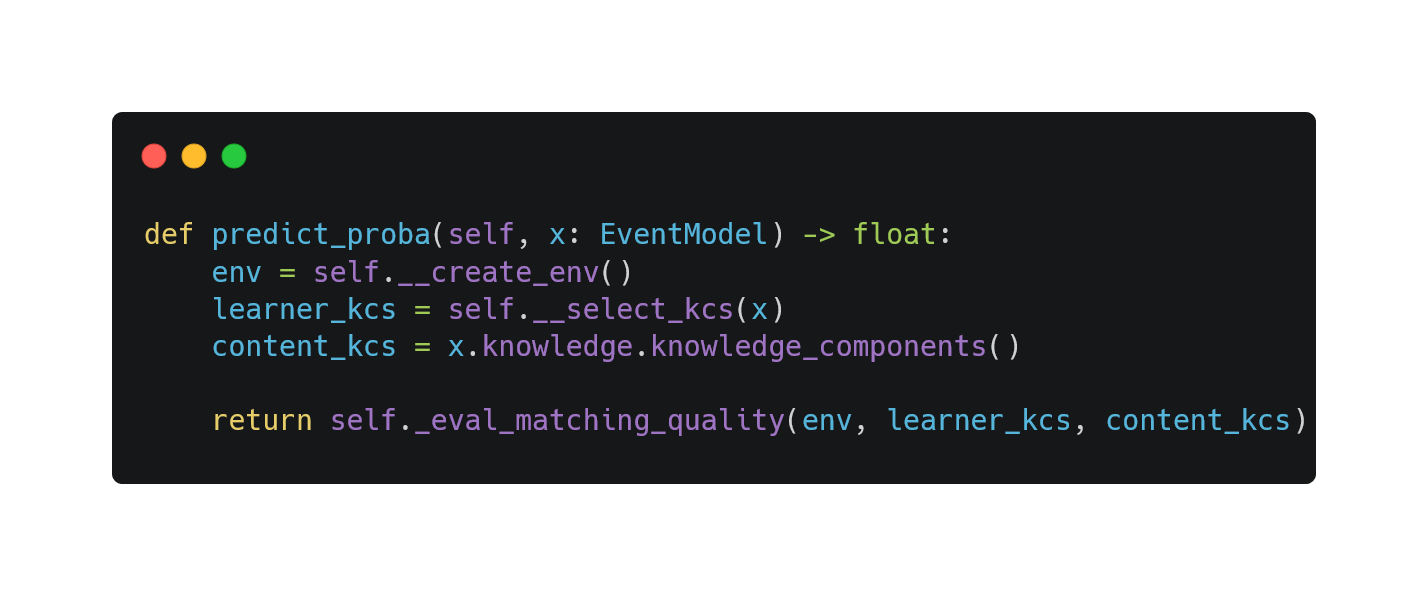
All three classifiers rely on decision threshold to output binary classification. Thus, we can define predict method like this:

For predict_proba, since each classifier relies on different assumptions, they have different ways to evaluate the matching quality between the learner and the learning event. It's worth noting that the return value of self._eval_matching_quality is between 0 and 1.
Loading Datasets
Truelearn comes with a datasets sub-package to load datasets. These datasets are useful to quickly illustrate the behaviour of the various classifiers implemented in truelearn.
Dependencies
- PEEK Dataset: a large, novel and open-source dataset of learners engaging with educational videos
Downloading the PEEK dataset
Since the size of the PEEK dataset is over 3MB, it is not feasible for us to embed it into truelearn as it would unnecessarily bloat our library. Therefore, we implement a download method to download the PEEK dataset from Github and use the sha256sum method to check the integrity of the downloaded file.
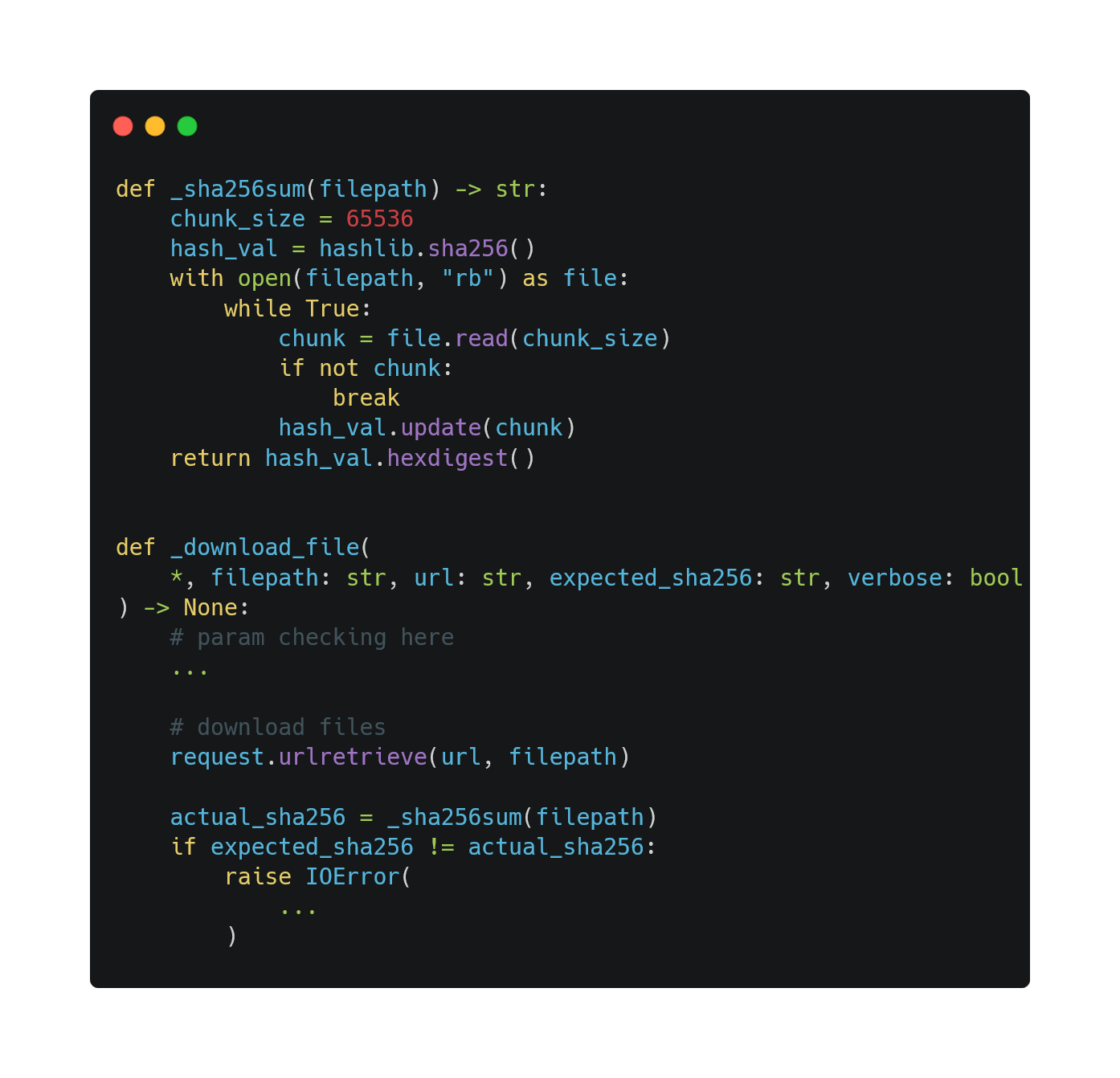
To avoid unnecessary downloading, we implement a simple cache mechanism based on sha256. We only download the file if the file does not exist or if the hash of the file does not match the expected hash.
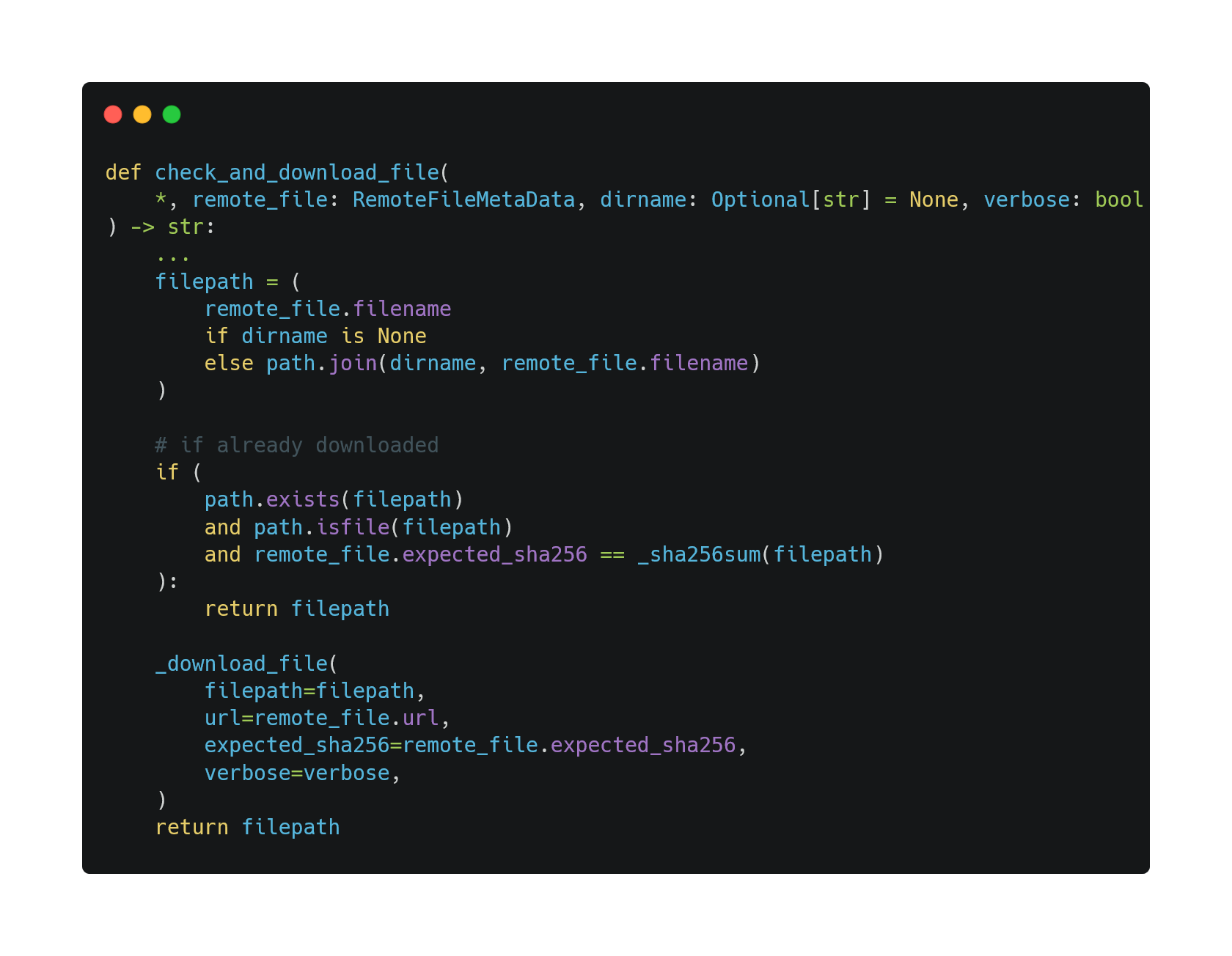
Parsing the PEEK dataset mapping
The PEEK Dataset contains an id_to_wiki_metadata_mapping.csv file which stores a mapping from Wikipedia id to its title, description, and url. It looks like this:
id,url,title,description
0,"https://en.wikipedia.org/wiki/""Hello,_World!""_program","""Hello, World!"" program",Traditional beginners' computer program
...Based on this format, we designed a __build_mapping method:
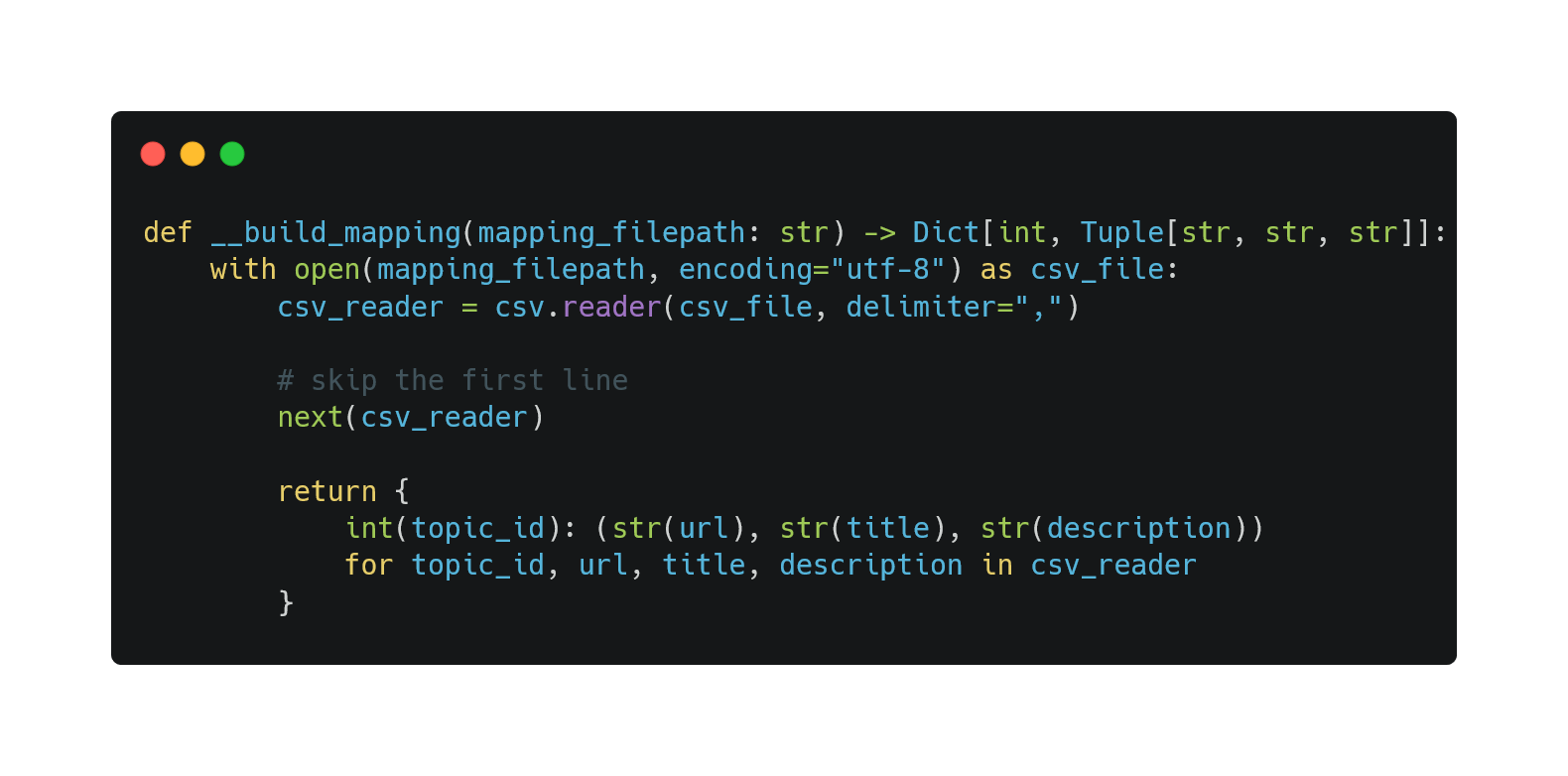
Parsing the PEEK dataset events
PEEK Dataset contains two other files train.csv and test.csv, which have the same format as shown below.

[1]
[1] S. Bulathwela, M. Perez-Ortiz, E. Novak, E. Yilmaz, and J. Shawe-Taylor, “PEEK: A Large Dataset of Learner Engagement with Educational Videos,” arXiv.org, 2021. https://arxiv.org/abs/2109.03154 (accessed Apr. 09, 2023).
By using this format, we can write two methods __restructure_line and __restructure_data.
In __restructure_line, we:
- Unpack the data
- Convert them to the correct types
- Construct KCs,
KnowledgeandEventModel - Return the
(learner_id, event_model, label)tuple
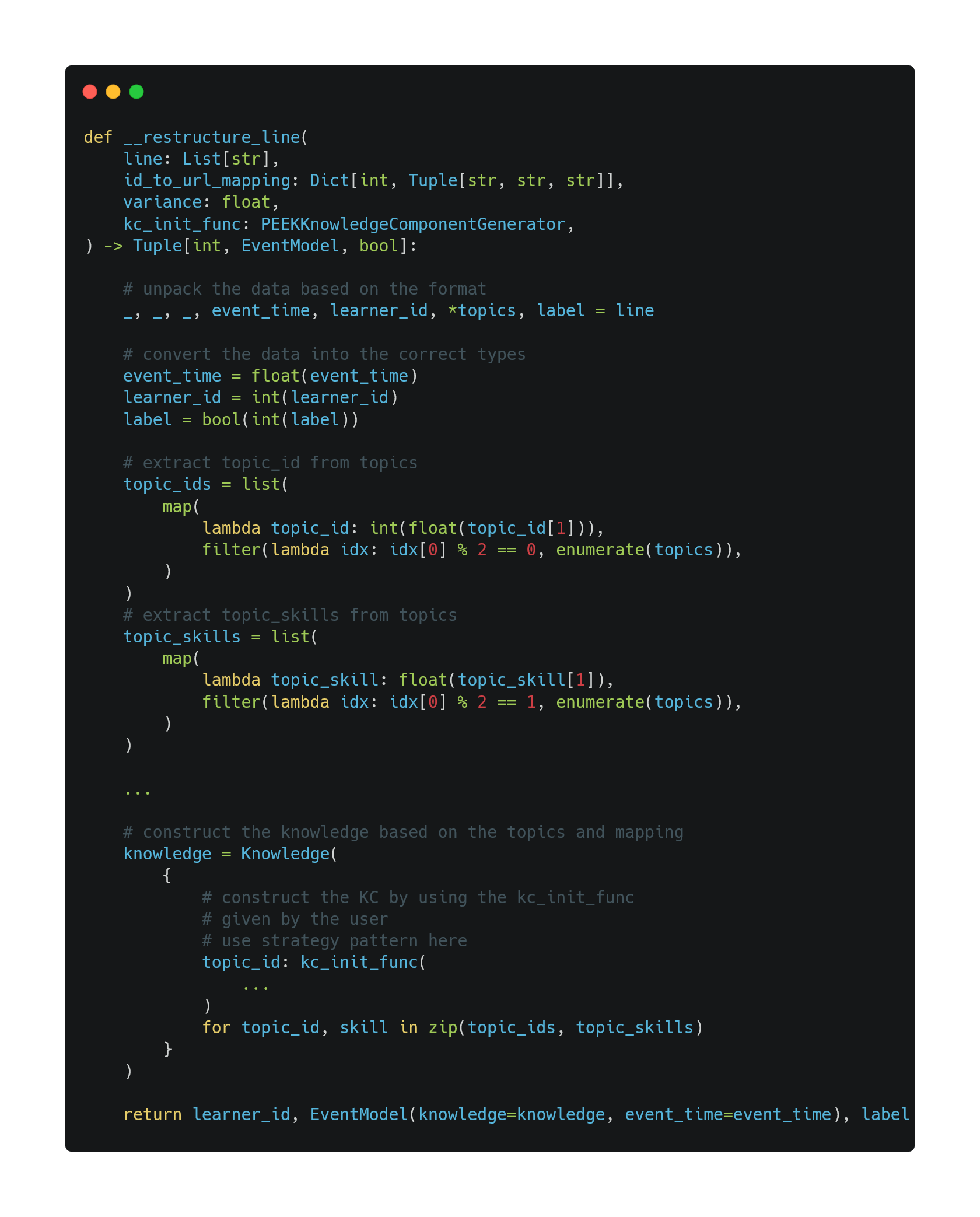
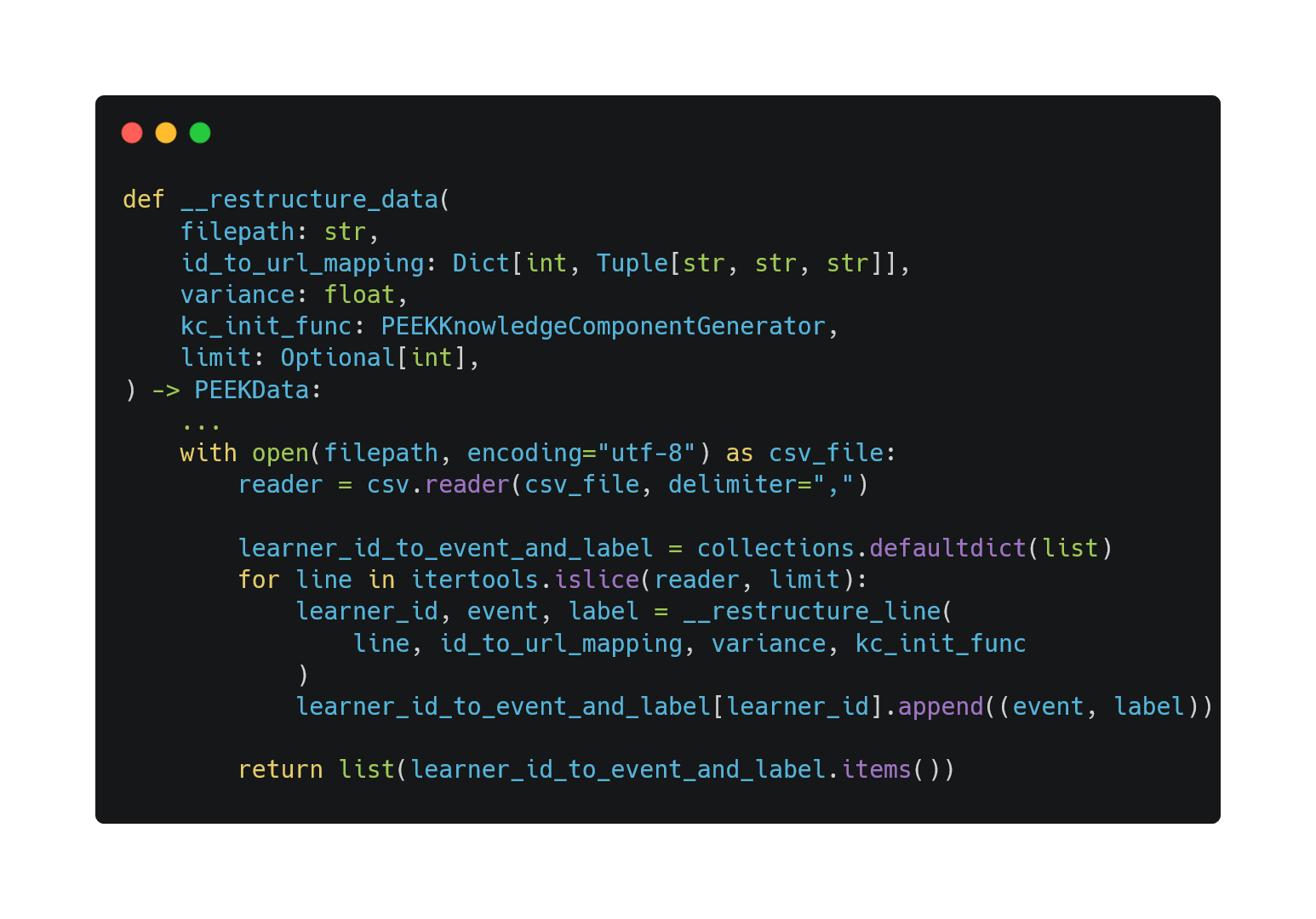
In __restructure_data, we
- Restructure each line by using
__restructure_line - Append the returned
EventModeland label to a dictionary - Return the dictionary in list format
Visualisations
The truelearn.utils.visualisations package equips users with tools to generate various visualisations.
Dependencies
- Matplotlib: the most popular Python graphing library for generating visualisations. Provides advanced customisation options for plots.
- Plotly: a Python graphing library built on top of Matplotlib. Provides fewer plots but charts generated with Plotly are interactive and can be exported to HTML.
Due to interactivity being a requirement for our project, we decided to use Plotly whenever possible and use Matplotlib only to generate charts that were not possible with Plotly.
BasePlotters
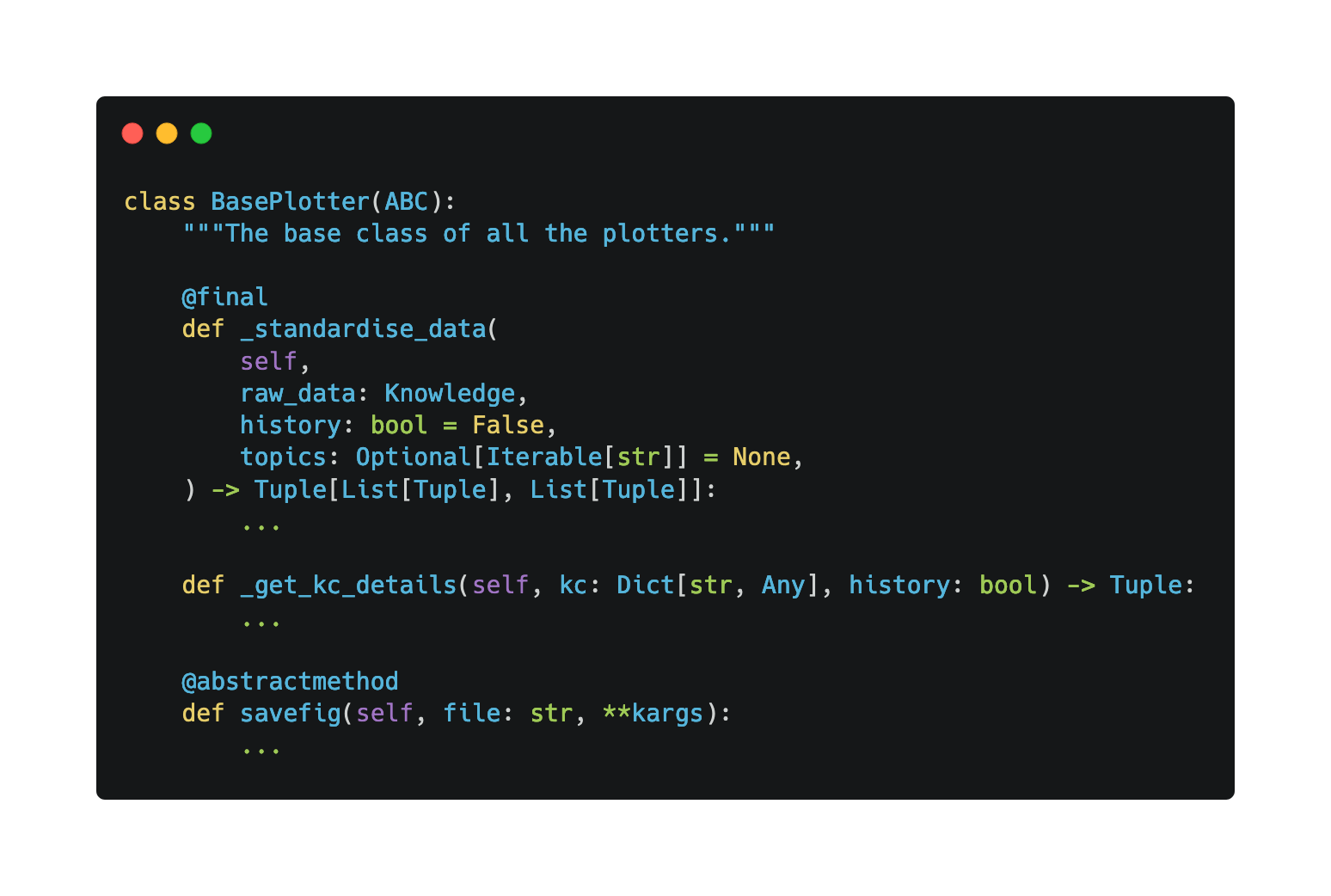
Initially we decided to write a series of plotters, with each plotter providing methods to generate a different visualisation and we designed a BasePlotter class to define the core methods across all plotters. These methods are:
_standardise_dataand_get_kc_details: to clean and standardise the data, converting a Knowledge object into something that could be used by Plotly and Matplotlib.savefig: to save the visualisation to an external file.
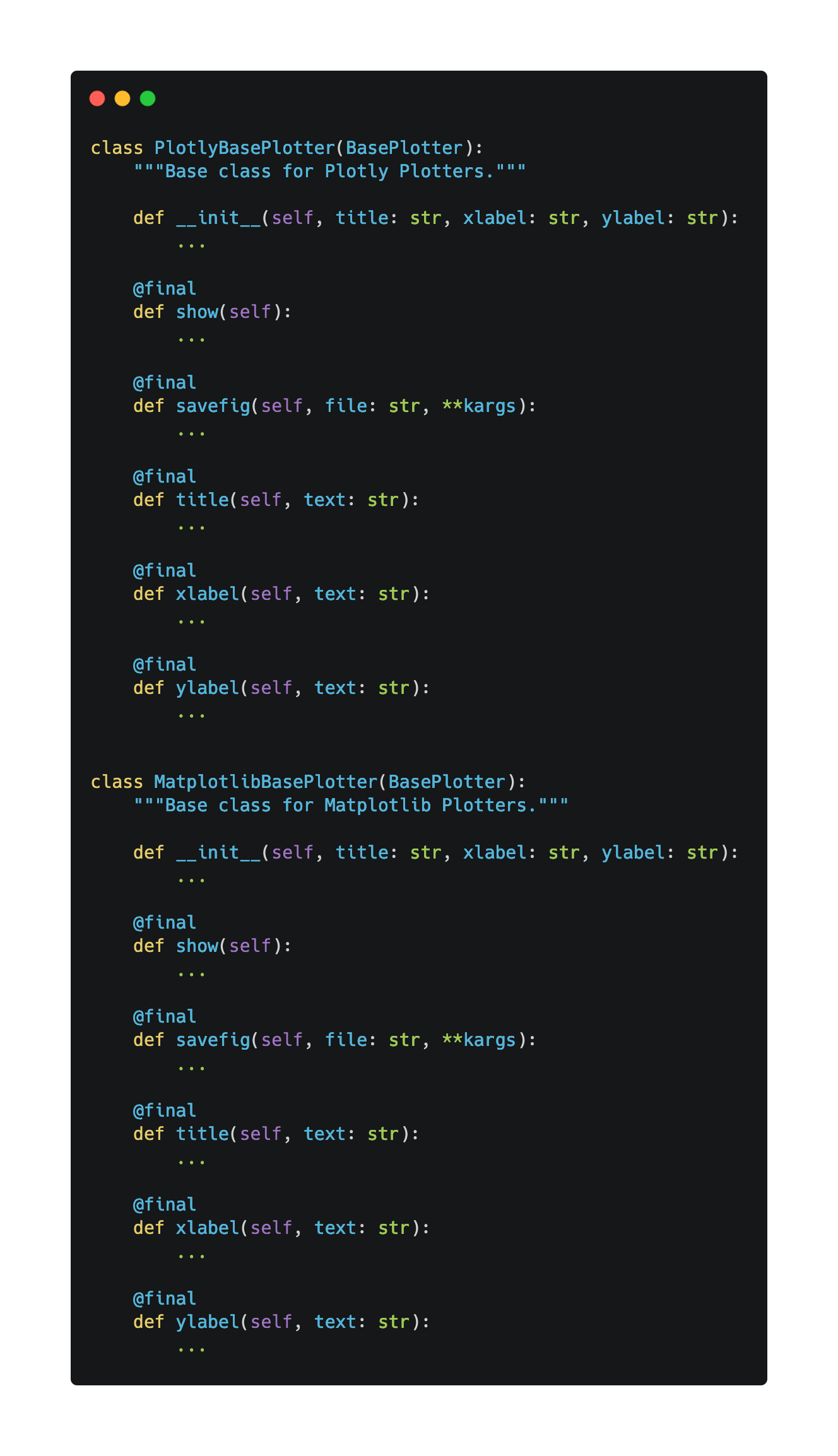
Since we had to generate visualisations with both Plotly and Matplotlib, we also created the BasePlotlyPlotter and BaseMatplotlibPlotter classes that inherit from BasePlotter and extend its functionality by adding methods unique to their respective graphing libraries. This way, we ensured that all current and future plotters would share the same interface regardless of the library they relied on.
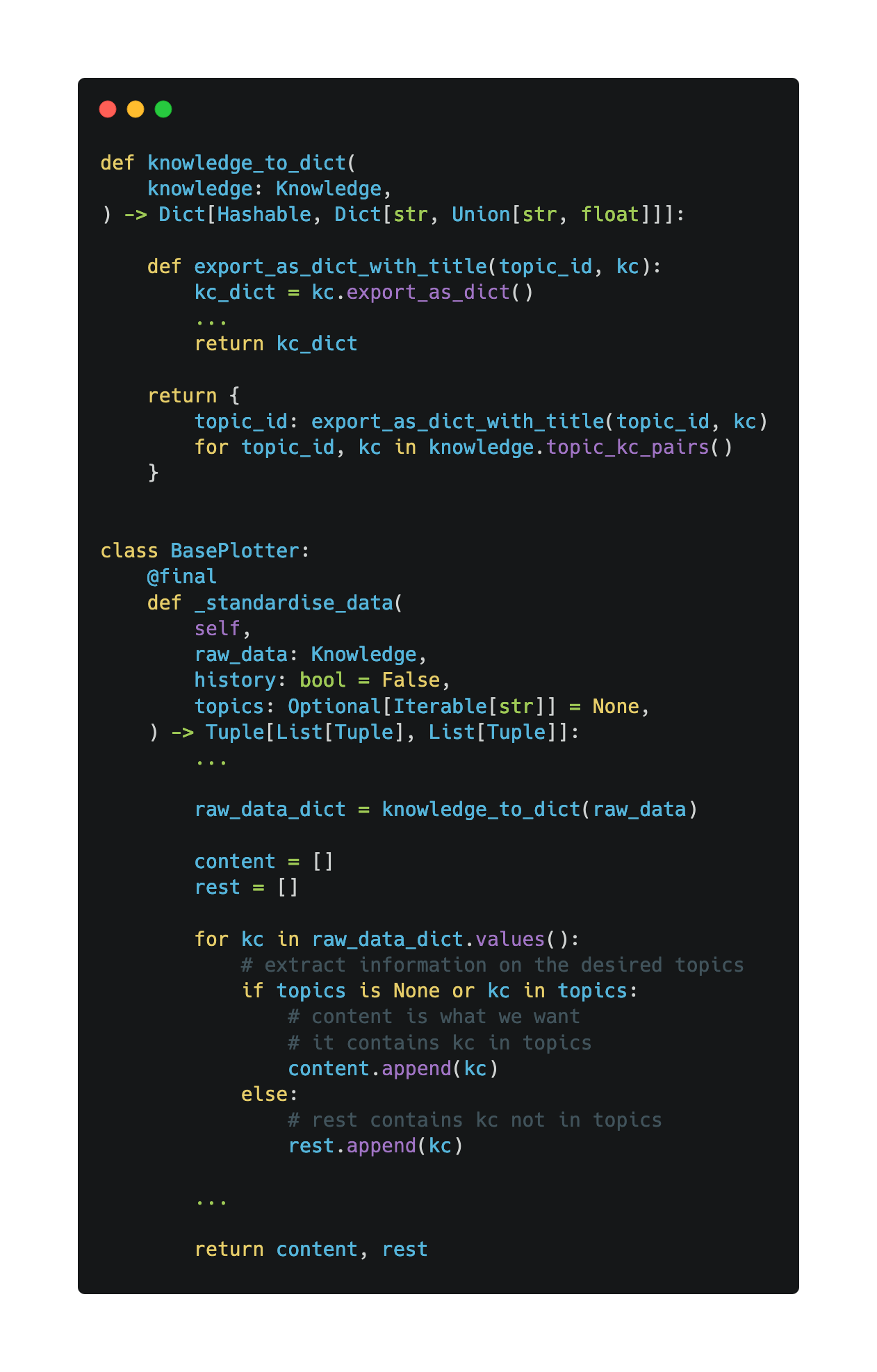
Preparing the data
In the _standardise_data method, we convert the given Knowledge object into a Python dictionary via the knowledge_to_dict function and we extract information on the desired topics from all the knowledge components.
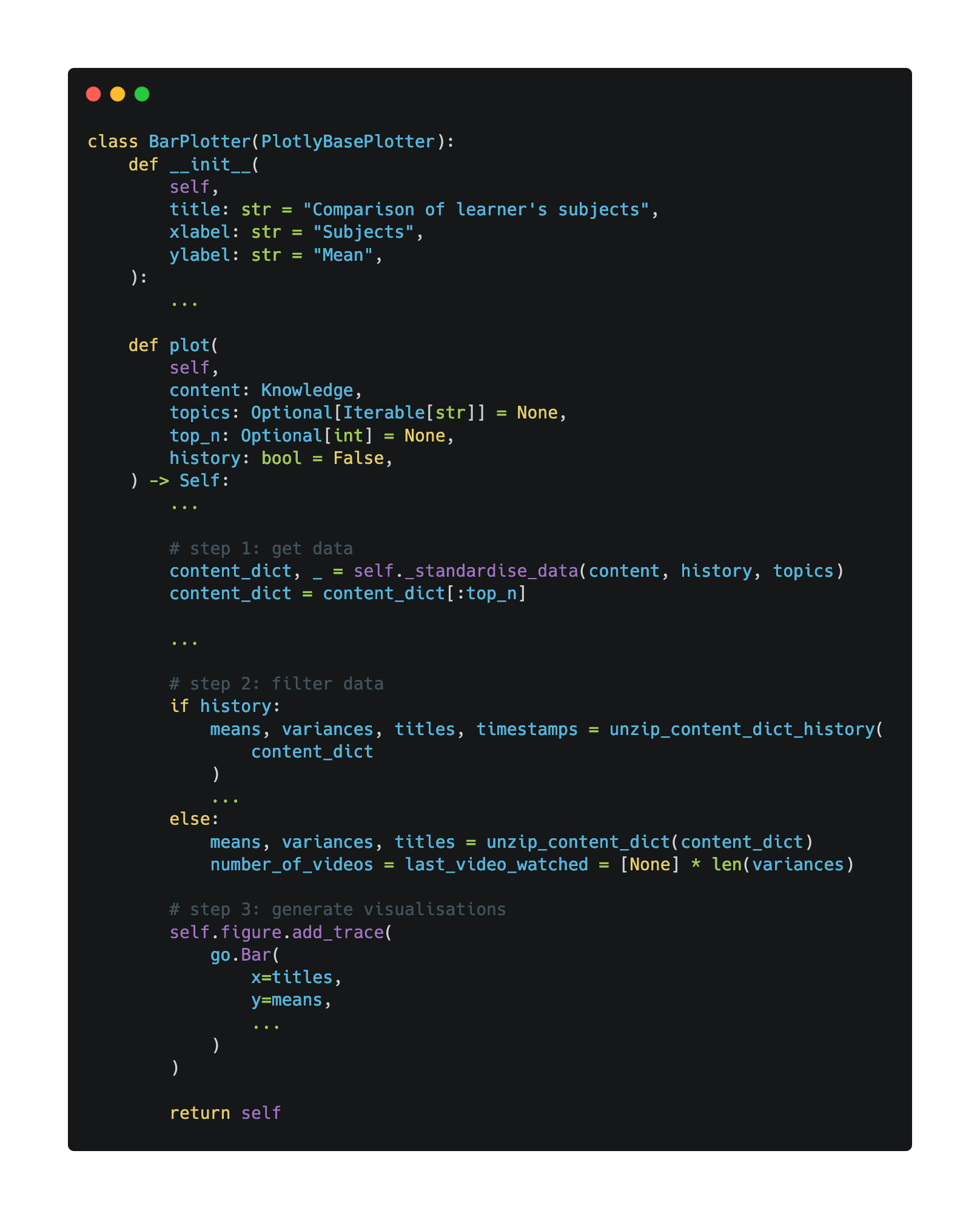
Plotting the data
The contents of the plot method vary for each plotter, but they all follow the same structure:
- Initially,
_standardise_datais called insideplotto clean the data. - The data returned from
_standardise_datais filtered to obtain the desired information to visualise in each chart. - Using the additional arguments passed in for customisation by the user (e.g. history), the visualisation is generated and stored in
self.
Saving the visualisation
Implementing this feature was straightforward since it's the same regardless of the plotter. The only difference came when considering whether the plotter relied on Matplotlib or Plotly. Making this distinction is important as different libraries provide different formats to export to. For example, with Plotly it is possible to export to HTML but that is not the case for Matplotlib. For now, the plotters are based on either Matplotlib and Plotly, so there are only 2 variations of the savefig method:
- The Matplotlib one:
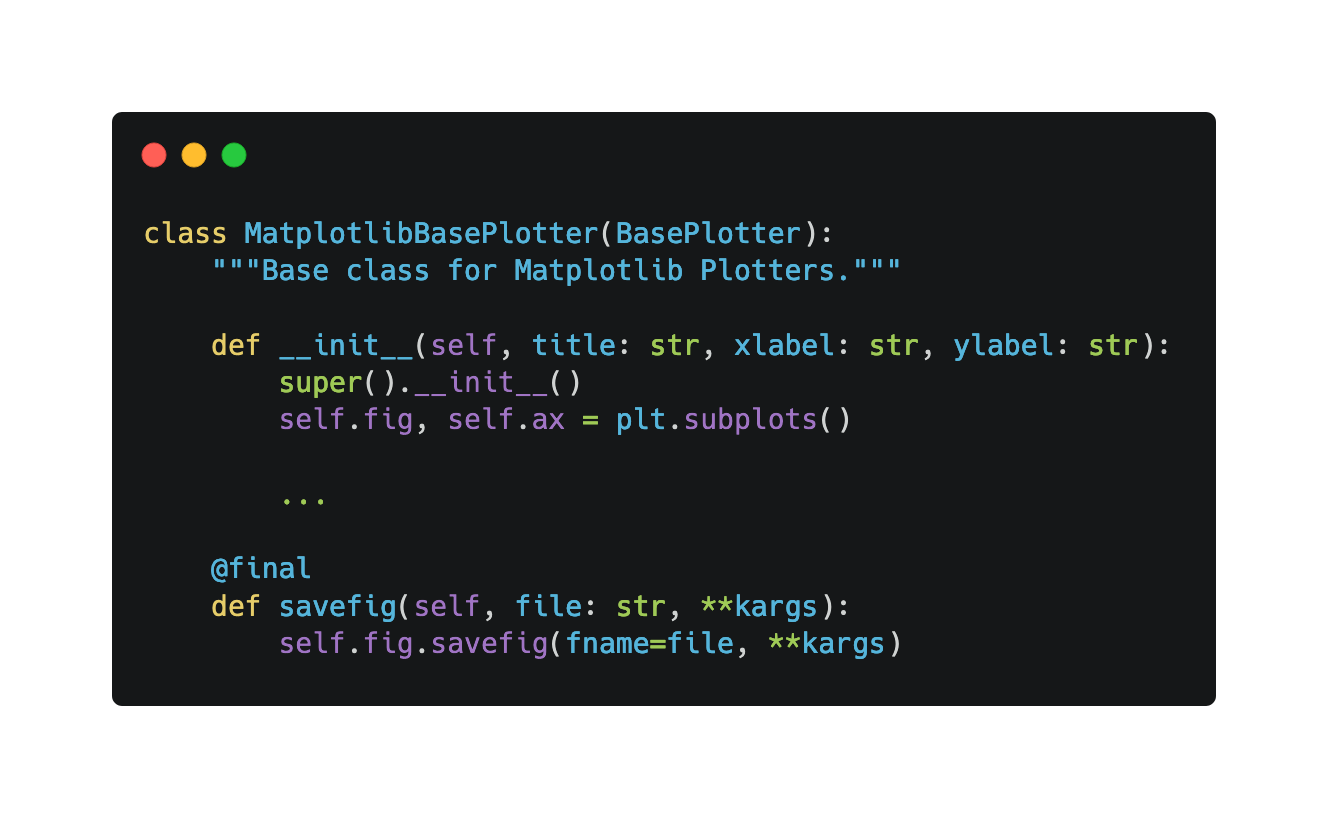
- and the Plotly one:
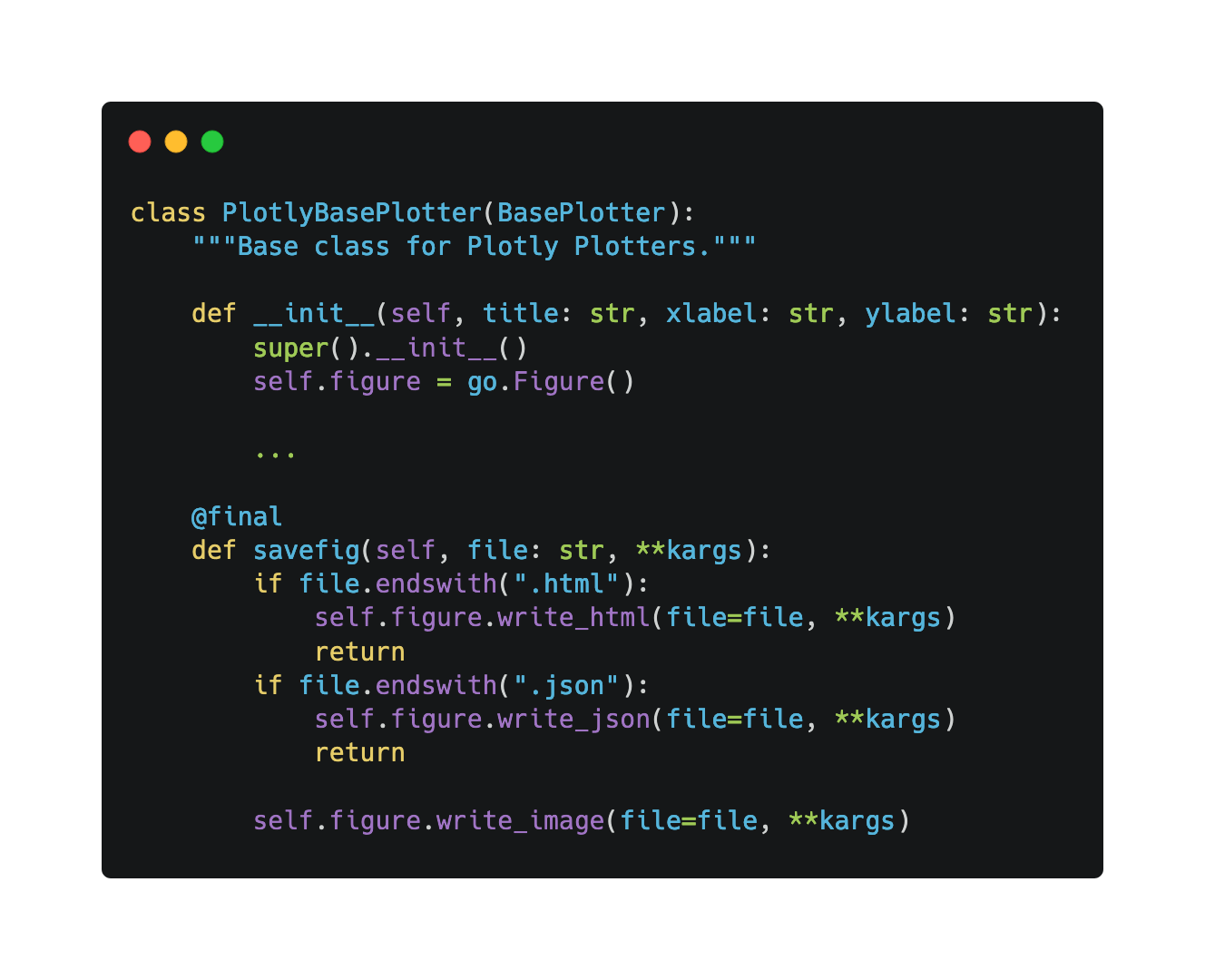
Additional Information
For more information concerning our implementation, please refer to the Design Considerations section of our documentation.